FlayerVEO 学无止境 - ········Python
http://124.222.113.99/index.php/category/python
-
Python 大数据 Pandas文件处理-读写HTML文件
http://124.222.113.99/index.php/archives/1909/
2020-02-13T16:02:00+00:00
#读写HTML文件:
##写入HTML文件:
1\. 创建DataFrame:
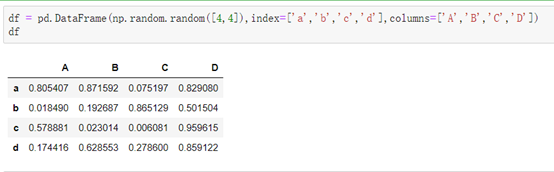
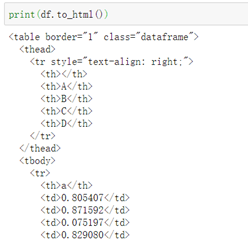
2\. 直接print出to_html()的内容可以发现将DataFrame转为了HTML中的格式
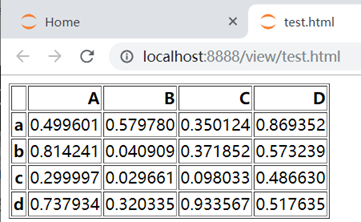
3\. 使用df.to_html('文件名') 保存至html文件中

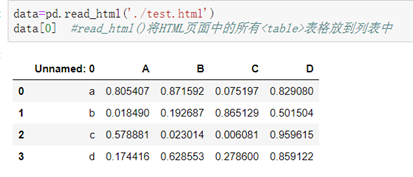
##读取HTML文件:
方法一:读取HTML文件
```python
格式:pd.read_html('HTML文件路径')
```
方法二:读取URL链接
```python
格式:pd.read_html('URL链接')
```
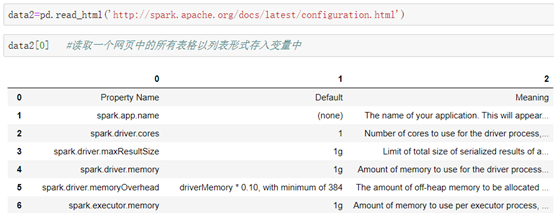
-
Python 大数据 Pandas文件处理-读写CSV和文本
http://124.222.113.99/index.php/archives/1902/
2020-02-13T16:00:00+00:00
##读写CSV文件:
什么是CSV文件:以逗号分隔元素的文本文件。
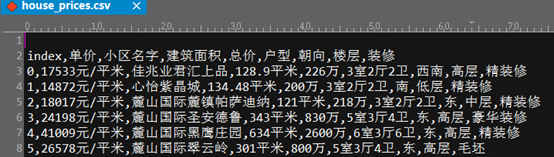
---
####读取CSV文件:
格式1:
```python
pd.read_csv('文件名')
```
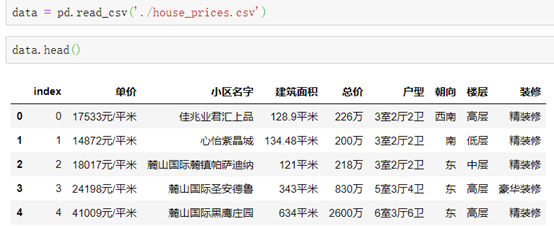
read_csv()的内置属性:
```python
1. header=None #下移标签行,以默认0、1、2....作为新标签代替。
2. names=[‘标签1’, '标签2', '...', '标签N'] #设置标签
3. skiprows=[‘N1’, 'N2', '....'] #删除(不读取)文件中的N1行,N2行......
4. nrows=N #只从文件中读取N行数据到变量中
```
--示例:
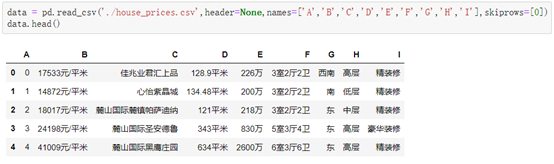
格式2:
```python
pd.read_table('文件名', sep='分隔符') #与read_csv()的区别在于read_table()必须要使用sep指定分隔符,read_csv()可以不用sep,因为默认分隔符为','。
```
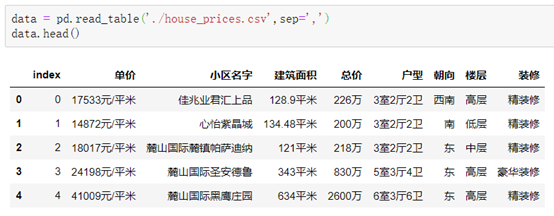
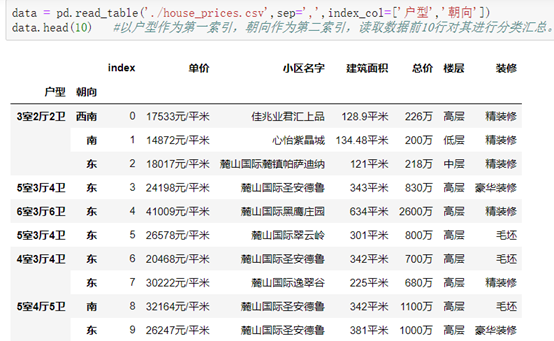
read_table()的内置属性:
```python
1. 包括read_csv()的所有属性。
2. index_col=['第1索引', '第二索引', '第N索引'] #将列作为索引对所有行进行分类。
```
--示例:
----
####写入CSV文件:
格式:
```python
"DataFrame".to_csv('文件名')
```
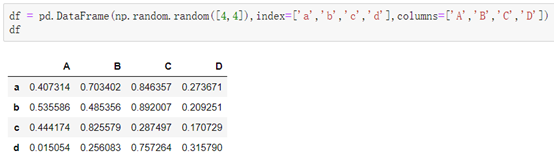
创建示例:
1.创建一个DataFrame以写入csv:
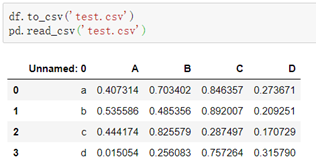
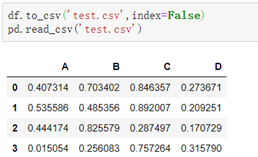
2.使用to_csv写入csv: (发现自定义的行标签并未起作用,读取时给了默认的行标签)
to_csv()的内置属性:
```python
1. header=False #删除当前列标签
2. index=False #删除当前行标签
3. na_rep='任意字符' #将DataFrame中的NaN数据以任意字符代替保存到csv中
```
--示例:
-
Python 大数据 Pandas - NaN数据处理
http://124.222.113.99/index.php/archives/1893/
2020-02-13T15:56:00+00:00
##NaN:
NaN数据即空数据,这种数据在数据处理中是非常常见的。
---
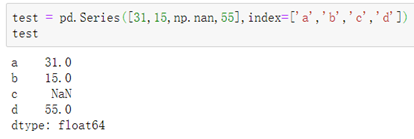
####一、初始化NaN数据:
使用numpy模块中的nan方法创建nan数据:
---
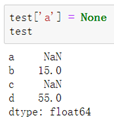
####二、赋值NaN数据:
直接赋值None即空数据:
---
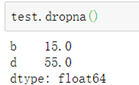
####三、Series删除NaN数据:
或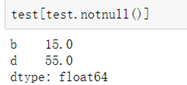
---
####四、DataFrame删除或处理NaN数据:
创建存在NaN数据的DataFrame:
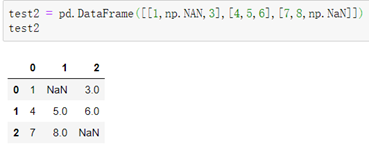
```python
格式1:DataFrame.dropna(axis=0/1,how="any/all") #删除NaN数据所在的行或列
```
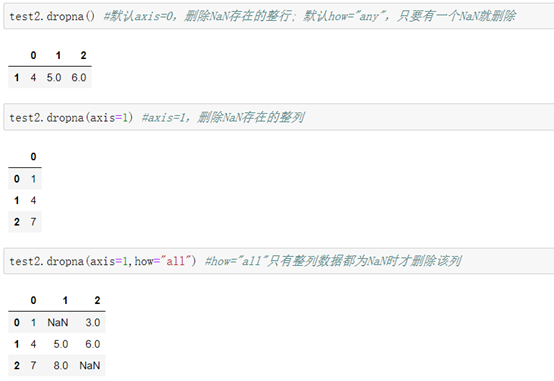
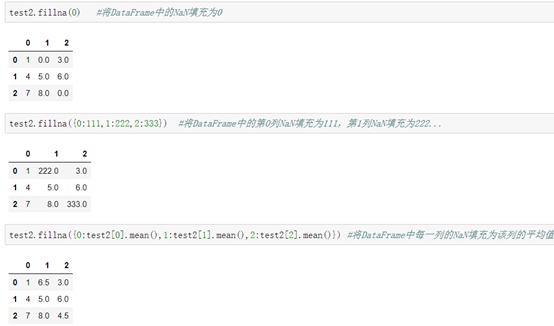
```python
格式2:DataFrame.fillna(填充数据) #将NaN数据填充为其他数据
```
-
Python 大数据 Pandas - 排序与排位
http://124.222.113.99/index.php/archives/1885/
2020-02-13T15:54:00+00:00
#排序与排位
排序通用方法: ascending(默认为True,正序排序;False逆序排序), axis=1(默认为0,按index行;1按columns列)
##排序:
####按索引排序:
格式:
```python
pd.sort_index(ascending=True/False, axis=0/1)
```
Series的排序:
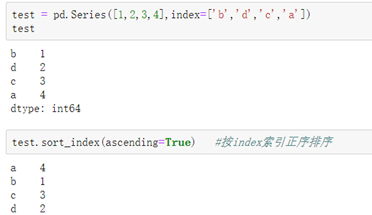
DataFrame的排序:
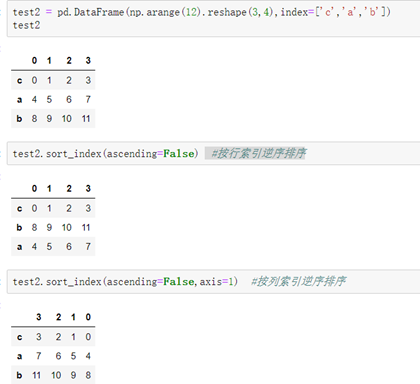
---
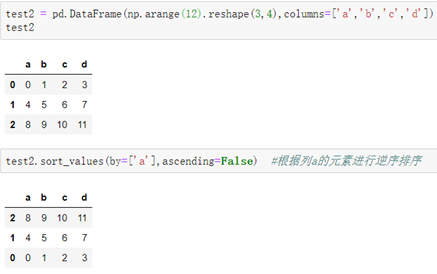
####按元素排序:
```python
格式: pd.sort_values( by=['列名'], ascending=True/False, axis=0/1)
```
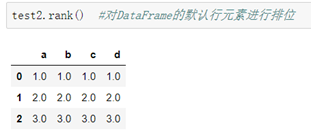
##排位:
```python
格式:pd.rank(ascending=True/False, axis=0/1)
```
Series的排位:
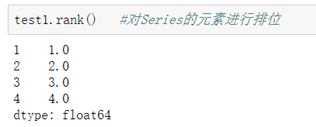
DataFrame的排位:
-
Python 大数据 Pandas - Numpy与自定义函数
http://124.222.113.99/index.php/archives/1879/
2020-02-13T15:53:00+00:00
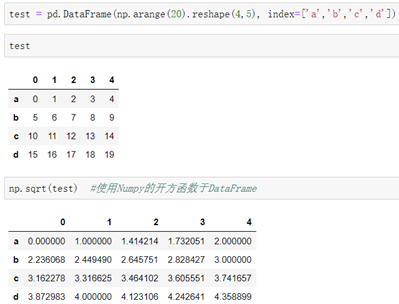
#Numpy函数的应用:
##作用于单个元素的函数:
介绍:Series和DataFrame数据可以像ndarray一样使用Numpy的方法。
例:
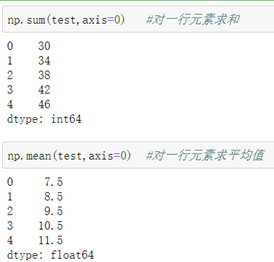
##作用于行列的函数:
```python
axis=0 表示求行元素; axis=1 表示求列元素。
```
##Apply自定义函数:
作用于单个元素的函数:
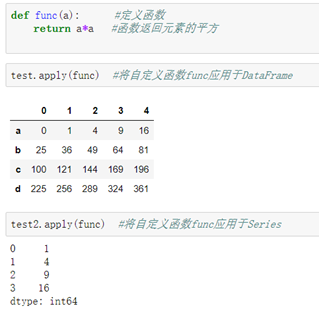
作用于一行或列的函数:
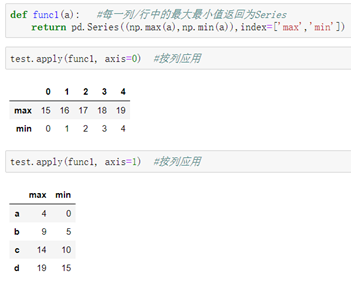
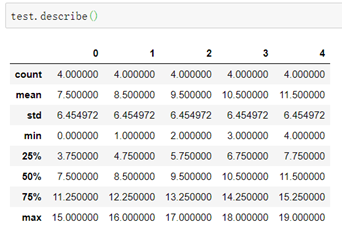
Pandas自带函数:
-
Python 大数据 Pandas - 数据结构之间的计算
http://124.222.113.99/index.php/archives/1873/
2020-02-13T15:51:00+00:00
介绍:DataFrame与Series之间的计算相当于Series与DataFrame每行对应索引之间计算。
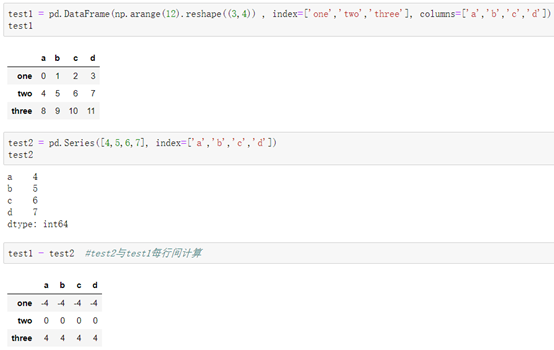
当DataFrame与Series之间的索引行标签不同时,所涉及的元素会以NaN空元素填充:
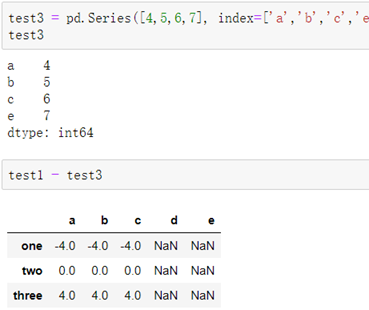
-
Python 大数据 Pandas - 数据结构-DataFrame
http://124.222.113.99/index.php/archives/1870/
2020-02-13T15:50:00+00:00
#数据结构-DataFrame
介绍:DataFrame数据结构和关系型表格类似,相当于将Series扩展到多维。由多列组成,各列数据类型可以不同。
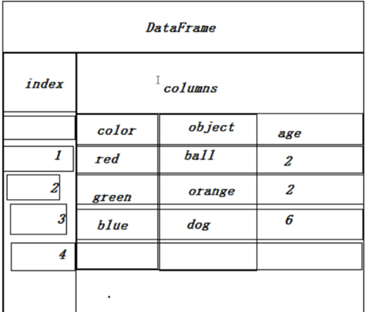
##一、 定义DataFrame:
统一格式:
```python
pd.DataFrame(矩阵,index=[行标签列表],columns=[列标签列表])
```
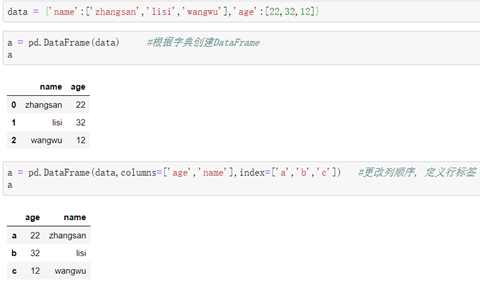
方式一:使用字典创建
介绍:字典中的键名对应DataFrame的列标签名;字典中的键值是个列表,代表每个列标签下的列元素。因为字典创建的DataFrame中已经带有列标签名,所以在创建DataFrame时不能再使用"columns="定义新的列标签,只能改变列标签的位置做到改变列的排列顺序。
例:
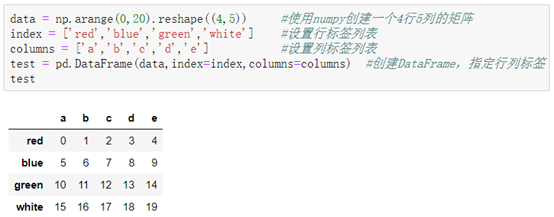
方式二:使用矩阵创建
介绍:最普遍的创建方式,使用numpy创建ndarray矩阵,这个方法因为没有初设行标签和列标签,所以可以自定行标签和列标签。
例:
##二、 属性的获取:
1.获取行标签:
```python
格式:DataFrame.index
```

2.获取列标签:
```python
格式:DataFrame.columns
```
3.获取DataFrame的ndarray矩阵:
```python
格式:DataFrame.values
```
4.获取某列或某几列的全部元素:
```python
格式1:DataFrame['列标签'] #获取一列的元素
格式2:DataFrame[ ['列标签1','列标签2',...] ] #获取多列的元素
```
5.获取某行或某几行的全部元素:
```python
格式1:DataFrame.ix['行标签'] #获取一行的元素
格式2:DataFrame.ix[ ['列标签1','列标签2',...] ] #获取多行的元素
```
6.获取某行到某行之间的全部元素:
```python
格式:DataFrame[i : j] #获取i+1行到j行的元素
```
7.获取某行某列的一个元素:
```python
格式:DataFrame['行标签']['列标签']
```
##三、 属性的修改:
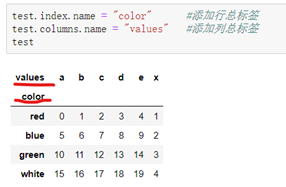
1.添加行的总标签:
```python
格式:DataFrame.index.name = "行总标签名"
```
2.添加列的总标签
```python
格式:DataFrame.columns.name = "列总标签名"
```
3.添加/修改某列的值:
```python
格式:DataFrame['列标签名'] = [列元素列表]
```

扩展:添加Series做新列

```python
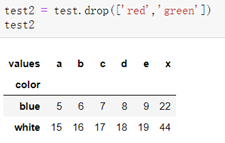
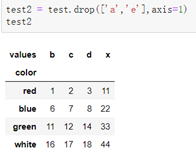
删除某列: del DataFrame['列标签']
删除几行: newDataFrame = DataFrame.drop(['行标签1','行标签2‘....])
删除几列: newDataFrame = DataFrame.drop(['列标签1','列标签2‘....],axis=1)
```
4.修改某个元素的值:
```python
格式:DataFrame['行标签']['列标签'] = 元素
```
##四、 其他的方法:
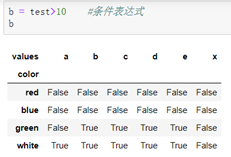
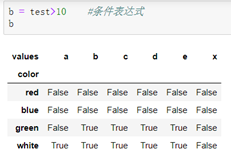
1.条件表达式:
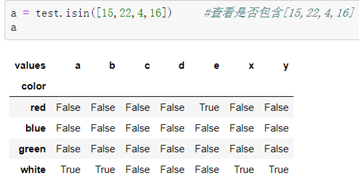
2.包含查询:
```python
格式:DataFrame.isin([列表])
```
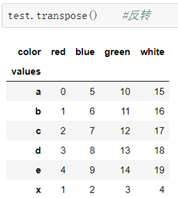
3.矩阵反转:
```python
格式:DataFrame.transpose() 或 DataFrame.T
```
-
Python 大数据 Pandas - 数据结构-Series
http://124.222.113.99/index.php/archives/1856/
2020-02-13T15:44:00+00:00
#数据结构-Series
介绍:Series结构的内部由两个相关联的数组组成,其中一个数组用来存放索引,另一个数组用来存放数据(numpy中的任意数据类型)。
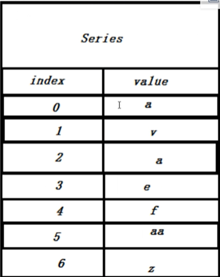
如图中两列左边一列作为存放索引的索引数组,右边一列作为存放数据的主索引。
1\. 导入模块:import pandas as pd
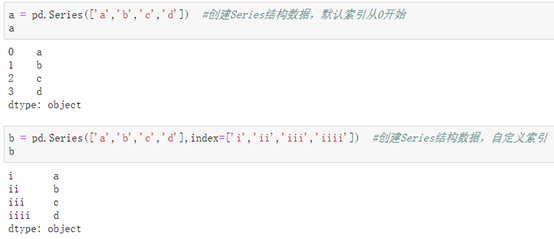
2\. 创建Series结构数据:
格式:pd.Series(数组, index=自定义索引列表) #放入的数组可以是列表元组字典或ndarray。
3\. 查看索引与元素的属性:

4\. Series的索引与切片:
介绍:格式与python列表的索引与切片相同,且Series还可以通过自定义索引的方式访问。
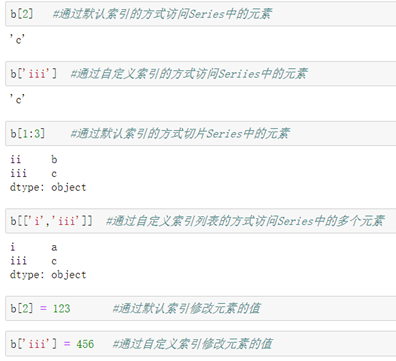
索引的删除: c = b.drop(['i'.'iii']) 将索引为'i'和'iii'的对应的两个元素删除。返回给新的Series。
5\. Series的比较与计算:
介绍:Series的计算和比较和Numpy一样,都是针对单个元素的。
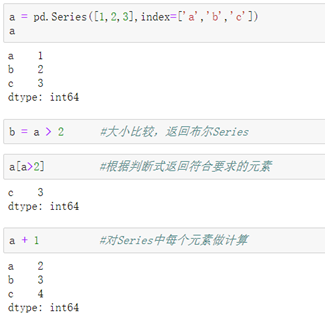
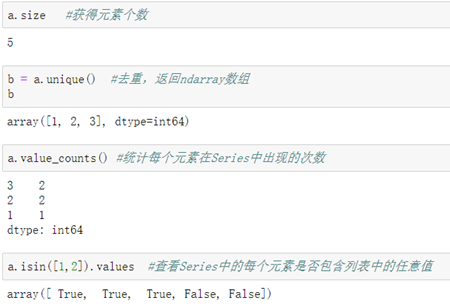
6\. Series的常用方法:
```python
a) 查看Series中的元素个数: .size() #返回整型
b) 对Series做元素去重: .unique() #返回ndarray数组
c) 对Series中的每个元素做出现次数的统计: .value_counts() #返回Series
d) 查看某列表中的数据是否出现在Series每个元素中: .isin([列表]).values
```
-
Python 大数据 numpy常用概念
http://124.222.113.99/index.php/archives/1849/
2020-02-13T15:42:21+00:00
副本和视图:
1.在numpy中队数组做运算或操作时,返回的结果不是副本就是视图。
2.在numpy中所有的赋值运算不会为数组和数组中的任何元素创建副本。例如:创建一个数组a,将a赋值给b,修改a中的元素,结果b中的元素也会被修改。实际上a和b指向同一个地址空间。
3.数组切片操作返回的对象是原数组的视图。
4.要生成一个完整的副本,需要使用copy函数()。例:矩阵B = 矩阵A.copy()
5.向量化:向量化和广播这两个概念是Numpy内部实现的基础,有了向量化,编写代码无需显示使用循环。这些循环不能省略,实际上在内部实现。向量化的结果是使代码更加简洁,可读性更强。
6.广播机制:广播机制这一操作,实现对两个或以上数组进行运算的功能,当两个形状不同的数组进行运算时,为了能使运算进行,需要对数组进行调整。
广播机制的适用条件:两个数组每一维等长或一个数组为1维。
广播机制的两条规则:第一条是缺失的维度补上1;第二条是如何扩展最小数组,使其跟最大数组大小相同。
-
Python 大数据 numpy - 数据文件的读写
http://124.222.113.99/index.php/archives/1848/
2020-02-13T15:41:00+00:00
#数据文件的读写:
##内部数据读写:
方法一:二进制保存读取
```python
保存:np.save('文件名', 矩阵名)
读取:np.load('文件名')
```
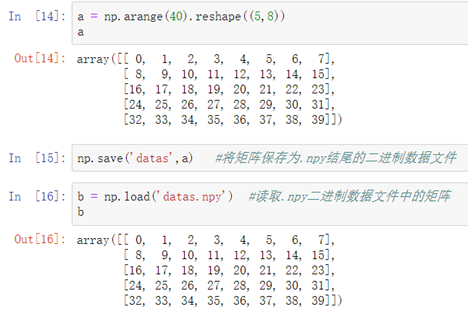
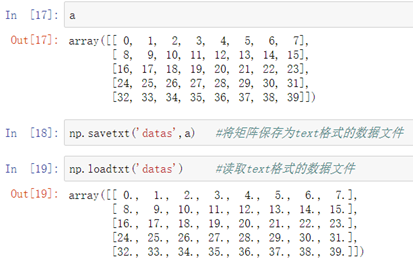
方法二:文本格式保存读取:
```python
保存:np.savetxt('文件名',矩阵)
读取:np.loadtxt('文件名')
```
##装载外部数据文件:
方法一:
```python
np.loadtxt('文件名', delimiter='分隔符', usecols=(需要读取的列索引), unpack=True, dtype=str)
```
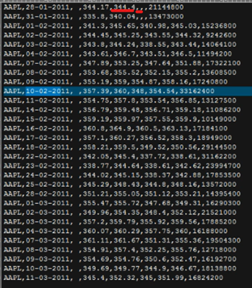
下图表示装载data.csv文件,以文件中的','为分隔符,选取索引分别为4和5的两列,做成h和l两个数据类型为字符串型的矩阵。(默认类型为float型,但因为数据中有空字符所以要转为str类型。)
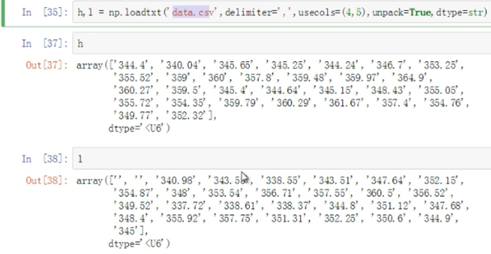
方法二:
```python
np.genfromtxt('文件名', delimiter='分隔符', names=True, usecols={需要读取的列索引}) #names表示是否读取第一行作为名字
```
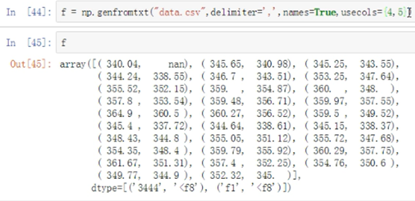
上图表示装载data.csv以','为分隔符,将索引为4和5的两列作为矩阵。